Interviews at the Joint Plenary: “Give me tools for it!”
During the Joint Plenary of NFDI4Earth and NFDI4Biodiversity we conducted 25 short Interviews to examine the need of semantic services across divergent institutions. Therefore we divided our interviews into two sections: while the questionnaire for Scientists [A] focussed on questions regarding publishing and reusing data, the one for Data Managers [B] referred to workflows for metadata management. Even though this study is not representative, some conclusions can be drawn about needs and gaps around metadata management.
In a Nutshell: 5 Key Insights
1. Broad interest in automated metadata enrichment
All interviewed scientists expressed strong interest in automated metadata enrichment to help publish FAIR data. However, enthusiasm was tempered by concerns about reliability, maintenance, and integration into existing publishing services (e.g., PANGAEA, Zenodo).
2. Metadata diversity and interoperability remain major challenges
Scientists use a wide variety of repositories and metadata standards (DataCite, ISO, INSPIRE, DarwinCore, etc.), showing a fragmented landscape. This heterogeneity limits interoperability and data reuse, emphasizing the need for semantic alignment and standardised metadata frameworks.
3. Richer metadata is crucial for data reuse and understanding
All scientists agreed that richer, more transparent metadata would enhance data comprehension and reuse. Desired metadata improvements include provenance, experimental context, spatial/temporal coverage, and data transformation history.
4. Data managers see automation and validation tools as high priorities
A strong majority of data managers (80%) believe that tools for metadata validation and automated data quality assurance would significantly streamline workflows. Even institutions with existing automation expressed a desire for further improvement in areas like term standardization using e.g. established ontologies, data annotation and cross-quality checks, as well as metadata extraction from publications.
5. Standardisation is acknowledged but inconsistently perceived
While few data managers explicitly reported a lack of standardization, most qualified their answers, acknowledging gaps in curation, internal data consistency, maintenance, and the lack of time. This indicates an awareness that standardisation is not fully achieved in practice, even if formally established.
Study Design & Outcome
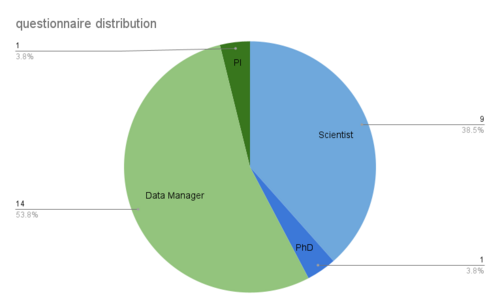
Overall we asked 25 people whereas 9 were Scientist and 14 classified themselves as Data Manager (in a broad sense, including repository staff and data stewards). One PhD Candidate was attributed to the Scientist and one PI to Data Manager which gave us a reasonable distribution of the different questionnaire sections.
Part A
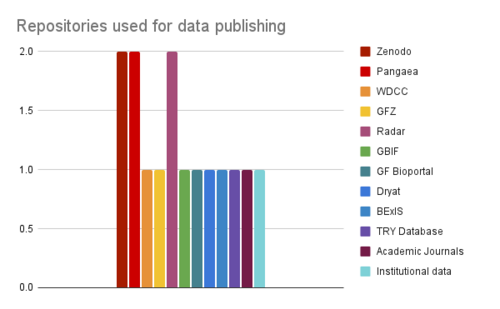
We asked the Scientists [A1] whether they publish data and if so, where and if not, why respectively. Out of 10 people only 2 did not publish data, the reason being ‘no time’ and ‘no need currently’. Repositories used for data publishing are widely spread ( multiple responses were possible) as are the metadata standards used (Datacite, ISO 19115/19139, INSPIRE, OGC sensor, Geonames, DarwinCore, ABCD, CF, ops4mips, archiveSS and project specific).
The question [A2] “Could automated metadata enrichment help you to publish your data as FAIR data?” was answered by all participants with “yes”, including the ones that currently do not publish data. Many participants emphasized their agreement with statements such as “yes, that would be really cool!” or “of course, give me tools for it!”. However, other remarks referred to the reliability of services (“yes that would help, but it must be maintained”, “only if it is reliable”), those using Zenodo as publisher restrained their statements (“only if Zenodo would implement it, I have no time”). Our last question [A3] “Do you (re)use data from others?” was answered with “yes” by 6 participants whereas again all respondents agreed that richer metadata would make data better understandable. The answers for the follow-up question “Which metadata would help you mostly” highlights the diverse landscape and a lack of interoperability options: “specific information about experiments”, “harmonisation of NCDF format”, “CF conformity”, “Provenance: who completed the data, original sources, applied data transformation”, “spatial/temporal coverage, parameter, resolution” and “more metadata for transparency, provenance, governance information” were mentioned.
Part B
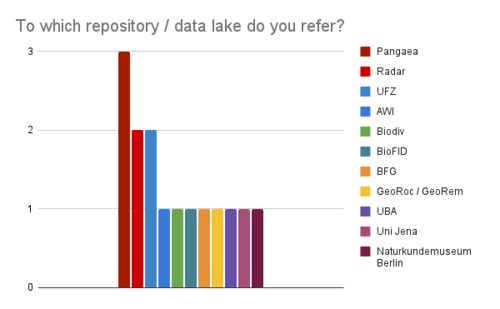
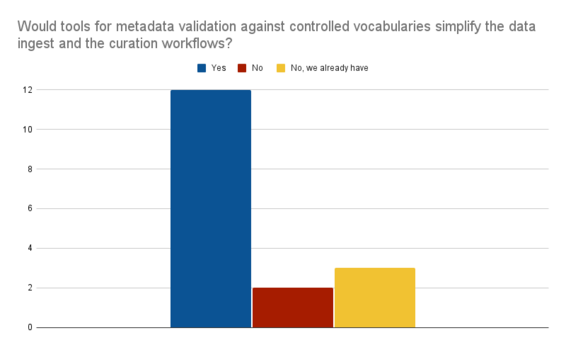
For Data Managers, the distribution across institutions/repositories is widespread as well. For our first question [B1] “Would tools for metadata validation against controlled vocabularies simplify the data ingestion and the curation workflows?” 12 participants responded with “Yes”, the other 3 persons claimed to have already automated workflows. However, here too, the answer “yes” was sometimes emphatically emphasized (“of course”, “certainly”). The second question [B2] “Are you looking for ways to automate your data quality assurance?” was answered by two-thirds of respondents with “Yes”. One-third responded with “No” but of those 3 were claiming that workflows for automated data quality assurance already exist. Interestingly, within the group of “Yes” some participants stated that even though they already have data quality mechanisms those could and should be improved (which is why they answered with “Yes”). The range for the follow-up question in which areas data quality assurance could be improved spans from “tools for term definition and standards”, “cross-quality checks” and “statistics and error dealing” to “tools for extracting metadata from papers”. Our final question [B3] “Are you concerned about the lack of standardisation in your repository / data lake asset?” shows no clear message: even though most participants do not recognise a lack of standardisation we got many restricting answers such as “no but curation is needed”, “not for published data but definitely for internal data”, “not for my repo, but certainly in general”, “no but curation and maintenance is an issue" or “no but there is much room for improvement”.